
Are your web pages not showing up in Google search results-even though they’ve been crawled? You’re not alone. A common SEO challenge many site owners encounter is seeing pages listed under the “Crawled – Currently Not Indexed” status in Google Search Console.
It’s a confusing and frustrating experience, especially when you’ve invested time and resources into building out your site content.
So, what exactly does “Crawled – Currently Not Indexed” mean? Why does it happen? And most importantly-how do you fix it?
Let’s dive deep into this issue and explore the most effective strategies to get your pages indexed and climbing the search rankings.
What Does “Crawled – Currently Not Indexed” Mean?
In Google Search Console, under the Coverage report, Google provides insights into how it is crawling and indexing your site.
When a page falls under the Excluded category with the status Crawled – Currently Not Indexed, it means:
- Google discovered your page
- Google crawled the page
- But Google chose not to index it
In simpler terms, Google visited the page, analyzed its contents, and determined-for now-that it’s not worth showing in search results.
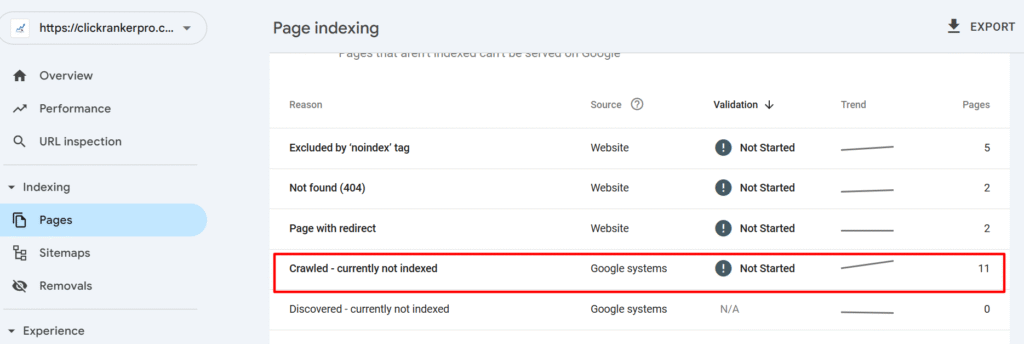
This is different from the Discovered – Currently Not Indexed status, where Google is aware of the page but hasn’t crawled it yet. With Crawled – Not Indexed, Google has already reviewed the page but decided it shouldn’t be added to the index.
This status signals a quality evaluation problem, not a technical crawling error.
Why Does It Happen?
There are several possible reasons:
1. Low-Quality or Thin Content
Google aims to serve users the most helpful, in-depth content. If your page has little content, or doesn’t go deep enough into a topic, it may be deemed unworthy of indexing. This includes pages with only a few lines of text, no visual media, or minimal value.
2. Duplicate Content
When Google finds multiple pages with identical or very similar content, it may choose to index only one. If your page doesn’t stand out or offer unique information compared to others (even on your own site), it may get excluded from the index.
3. Insufficient Internal Linking
Googlebot relies on internal links to discover and evaluate content. A page that’s hard to find through your site’s main navigation or internal links can be seen as isolated or unimportant, which can lead to it being skipped from indexing.
4. Previously Marked as “Noindex”
If your page previously had a “noindex” directive in the HTML or HTTP header, Google may have flagged it. Even if you’ve removed the directive, Google can delay re-evaluating the page, keeping it out of the index for a while.
5. Content Still Under Evaluation
Sometimes Google crawls a page but doesn’t immediately index it. The system might hold off until it’s confident the page meets quality standards or adds value beyond what’s already indexed. This evaluation phase can vary in duration.
6. New Page or New Website
If your site or page is relatively new, it might not yet have enough signals (like authority, structure, or popularity) to warrant immediate indexing. Google tends to be more selective when crawling newer domains or fresh content.
7. Complex or Parameter-Filled URLs
URLs that contain long strings of parameters or tracking codes can be seen as confusing or redundant by crawlers. Google may decide to skip indexing such URLs if it suspects they are duplicates or offer little original content.
8. Page Load Errors or Timeouts
When Googlebot attempts to crawl a page that doesn’t load correctly or takes too long, it may choose not to index the content. Errors like 5xx server responses, timeout delays, or incomplete loading can negatively impact the indexing decision.
9. JavaScript-Dependent Content
If key content is only loaded via JavaScript (like dynamically inserted text or images), it may not be fully visible during Google’s crawl. In such cases, Google may crawl the page but avoid indexing it due to missing or obscured content.
10. Very Similar Content Across Pages
If you have many pages with very minor variations (e.g., city-specific service pages or product pages with the same description), Google might only index the most representative version and skip the rest to avoid redundancy.
11. Not Included in Sitemap
Although Google can discover pages without sitemaps, being absent from a sitemap may lower a page’s priority. Google often prioritizes sitemap-listed content for indexing, and might overlook others unless they’re otherwise prominent.
12. Improper Canonical Tags
If a page contains a canonical tag pointing to another URL, Google interprets that as a signal that the other page should be indexed instead. Even if the content is slightly different, the canonical tag can lead to your page being skipped.
13. Lack of External or Internal Authority Signals
Pages that aren’t linked from authoritative parts of your site — or don’t have any links from other sites — can appear insignificant to Google. In such cases, the crawler may visit but not find a strong reason to index the page.
14. Redirect Chains or Loops
When a page involves multiple redirects before reaching its final destination, Google might get stuck or give up during crawling. Even if the destination loads, the process can signal instability, affecting the indexing decision.
15. Too Many Low-Value Pages Across the Site
If your website has a high proportion of low-quality or outdated pages, Google may slow down crawling or limit indexing for new content. This is based on its overall evaluation of the site’s trustworthiness and quality.
16. Mobile Usability Problems
Pages that are hard to use or unreadable on mobile devices — especially during mobile-first indexing — may be deprioritized. This includes layout issues, overlapping text, or elements that don’t display correctly.
17. hreflang or International Targeting Errors
For multilingual or multi-regional sites, incorrect hreflang implementation can cause confusion about which version of a page should be indexed. If hreflang signals are inconsistent or contradictory, Google may skip indexing the affected pages.
Let’s be clear: Just because a page was crawled doesn’t mean it’s guaranteed to be indexed.
Google’s index is selective. If it determines that a page doesn’t meet its quality threshold, it won’t include it in the index-meaning the page won’t rank or appear in search results.
How to Fix “Crawled – Currently Not Indexed”
If you’re seeing many important pages excluded with this status, you need to take proactive steps. Below are six proven strategies to improve your chances of getting indexed.
Check for Crawl Errors
Technical problems may have occurred during crawling.
What to do:
- In Google Search Console, check Coverage → Excluded.
- Look for server errors (5xx), redirect loops, or timeouts.
Fix any backend issues that might affect crawling.
Improve Page Load Speed
A slow-loading page can hurt crawl behavior and indexing.
What to do:
- Compress images.
- Minify CSS and JavaScript.
- Use caching and a CDN (Content Delivery Network).
Test your speed with tools like:
- PageSpeed Insights
- GTmetrix
Ensure No “Noindex” Meta Tags Are Present
You may have unintentionally told Google not to index the page.
What to do:
- Check the page’s source code for:
<meta name=”robots” content=”noindex”> - If it’s there, remove or update it.
Avoid JavaScript-Only Content
If your content is only rendered via JavaScript, Google might not see it.
What to do:
- Use server-side rendering or static HTML where possible.
- Test your page with Google’s “Mobile-Friendly Test” or “Rich Results Test” to see what Google sees.
Resubmit the URL in Search Console
Sometimes a simple re-crawl request helps.
What to do:
- Go to URL Inspection Tool.
- Paste the affected URL.
- Click “Request Indexing.”
Note: This doesn’t guarantee indexing but gives Google a nudge.
Make Sure It’s in Your XML Sitemap
Google pays more attention to pages listed in your sitemap.
What to do:
- Add the URL to your sitemap.
- Re-submit the updated sitemap in Google Search Console.
Create High-Quality, Unique Content
The #1 reason Google may skip indexing a page is because it thinks the content isn’t valuable or original.
If your content is:
- Auto-generated or spun
- Too generic
- Poorly structured
- Repetitive with other pages on your site
…then it’s unlikely to get indexed.
What to do:
- Ensure each page has unique, relevant content
- Add depth-cover the topic comprehensively
- Provide original insights, not just reworded articles
- Add visuals like custom graphics, charts, or videos to enrich the content
- Use structured headings, short paragraphs, and bullet points
💡 Pro Tip: If you used AI tools to generate the page, review and edit manually to enhance quality and originality.
Avoid Thin Content
Thin content refers to pages with little to no text or insufficient information.
A page with 100 words, a couple of images, and minimal value won’t impress Google. Even e-commerce product pages with only specs and no real descriptions can be considered thin.
What to do:
- Aim for at least 300-500 words of well-written content
- Add value: FAQs, comparisons, use-cases, testimonials
- Avoid publishing placeholder or “coming soon” pages
Even visual-heavy pages (like galleries) need accompanying textual context to be index-worthy.
Use Canonical Tags Correctly
Canonical tags help Google understand the original version of similar or duplicate pages.
If your page is missing a canonical tag or points incorrectly to another page, Google may choose to skip indexing.
What to do:
- Add a <link rel=”canonical” href=”your-page-url”> tag in the <head> of each page
- Ensure the tag points to the same page, unless you’re intentionally consolidating duplicates
- Use tools like Screaming Frog or Ahrefs to audit canonical issues
Strengthen Internal Linking
If Google crawls a page but doesn’t see it linked anywhere else on your site, it may assume it’s not important.
What to do:
- Link to the page from other relevant, high-authority pages on your site
- Use keyword-rich anchor text
- Make the page part of a logical content hierarchy or topic cluster
Google uses internal links to understand your site’s structure. Strong internal linking signals importance and encourages indexing.
Build Backlinks
Backlinks (links from other websites to yours) are a strong trust and authority signal.
If your unindexed page has no backlinks, Google may see it as unimportant.
What to do:
- Reach out to industry blogs or partners to link to your content
- Submit guest posts that link to your page
- Share your content in online communities and forums (Reddit, Quora, niche communities)
Even a few quality backlinks can boost your chances of indexing dramatically.
Share on Social Media (Especially Twitter/X)
Google doesn’t index everything shared on social media, but platforms like Twitter/X are regularly crawled.
What to do:
- Share the unindexed page on Twitter, Facebook, LinkedIn, etc.
- Tag relevant accounts or use industry hashtags
- Encourage others to engage with the post
This can increase discovery, traffic, and external signals that may influence Google’s indexing decisions.
Update the Page Frequently
If the page is stale or old, Google might deprioritize it.
What to do:
- Add new stats, insights, or content regularly.
- Refresh the publish date if the update is meaningful.
How Long Does It Take for Google to Index Changes?
Even after implementing the above changes, it may take days to weeks for Google to re-crawl and index your page. There’s no guaranteed timeline.
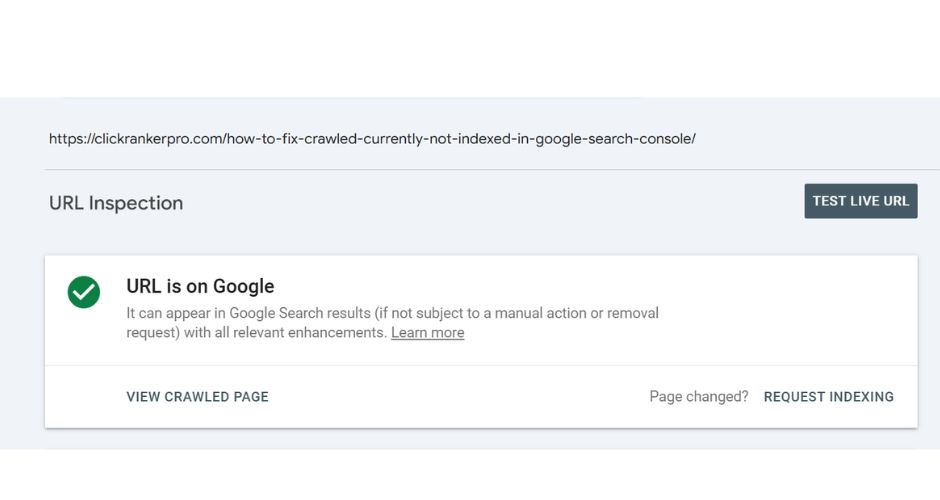
Here’s what you can do:
- Use the URL Inspection Tool in Google Search Console
- Click “Request Indexing” for updated or fixed pages
- Monitor the status after a few days
If Google still chooses not to index the page, keep improving it and promoting it externally.
Final Thoughts
The “Crawled – Currently Not Indexed” status can be discouraging-but it’s also a valuable signal.
It tells you that Google found your page but didn’t believe it was worth showing to users. That’s a chance to improve.
To fix it:
- Publish high-quality, unique content
- Avoid thin or duplicated content
- Use canonical tags properly
- Build internal links to the page
- Earn a few external backlinks
- Share your page socially (especially on X/Twitter)
Remember: You can’t force Google to index your content-but you can earn it by demonstrating value, authority, and relevance.
Keep improving, keep optimizing, and eventually, your pages will earn their place in the index-and the rankings.
FAQs
Q1. How long does it take for Google to index a page?
It can take a few days to several weeks, depending on the domain authority, content quality, and promotion efforts.
Q2. Can backlinks help with indexing?
Yes! High-quality backlinks signal to Google that your content is authoritative and worthy of indexing.
Q3. Should I delete pages that are not being indexed?
Only if they provide no unique value or cannibalize other indexed pages. Otherwise, improve and resubmit.
Q4. Is it okay to keep a page live if it’s not indexed?
Yes, but it’s better to fix the issue. Non-indexed pages can dilute your crawl budget and may signal poor content quality.
Related Articles:
How To Fix “Blocked due to unauthorized request (401)” in Google Search Console

